Conceptos de Alto Nivel
Esta documentación ha sido traducida automáticamente y puede contener errores. No dudes en abrir una Pull Request para sugerir cambios.
LlamaIndex.TS te ayuda a construir aplicaciones impulsadas por LLM (por ejemplo, Q&A, chatbot) sobre datos personalizados.
En esta guía de conceptos de alto nivel, aprenderás:
- cómo un LLM puede responder preguntas utilizando tus propios datos.
- conceptos clave y módulos en LlamaIndex.TS para componer tu propia canalización de consultas.
Responder Preguntas en tus Datos
LlamaIndex utiliza un método de dos etapas al utilizar un LLM con tus datos:
- etapa de indexación: preparar una base de conocimientos, y
- etapa de consulta: recuperar el contexto relevante de los conocimientos para ayudar al LLM a responder una pregunta.
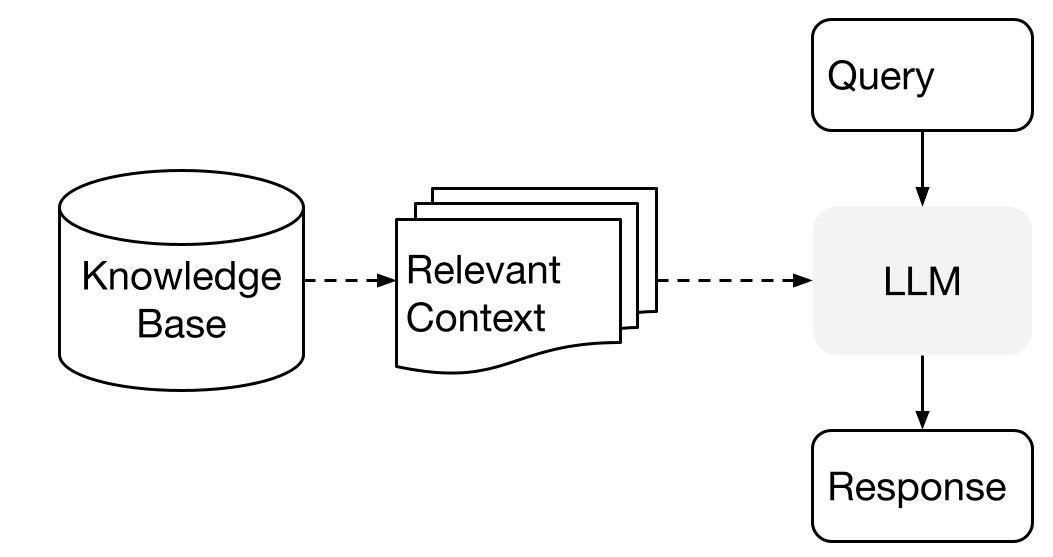
Este proceso también se conoce como Generación Aumentada por Recuperación (RAG).
LlamaIndex.TS proporciona el conjunto de herramientas esenciales para hacer que ambos pasos sean muy fáciles.
Vamos a explorar cada etapa en detalle.
Etapa de Indexación
LlamaIndex.TS te ayuda a preparar la base de conocimientos con una serie de conectores de datos e índices.

Cargadores de Datos:
Un conector de datos (es decir, Reader) ingiere datos de diferentes fuentes y formatos de datos en una representación simple de Document (texto y metadatos simples).
Documentos / Nodos: Un Document es un contenedor genérico alrededor de cualquier fuente de datos, por ejemplo, un PDF, una salida de API o datos recuperados de una base de datos. Un Node es la unidad atómica de datos en LlamaIndex y representa un "fragmento" de un Document de origen. Es una representación completa que incluye metadatos y relaciones (con otros nodos) para permitir operaciones de recuperación precisas y expresivas.
Índices de Datos: Una vez que hayas ingresado tus datos, LlamaIndex te ayuda a indexar los datos en un formato fácil de recuperar.
Bajo el capó, LlamaIndex analiza los documentos en representaciones intermedias, calcula incrustaciones vectoriales y almacena tus datos en memoria o en disco.
Etapa de Consulta
En la etapa de consulta, la canalización de consultas recupera el contexto más relevante dado una consulta del usuario, y lo pasa al LLM (junto con la consulta) para sintetizar una respuesta.
Esto le brinda al LLM conocimientos actualizados que no están en sus datos de entrenamiento originales, (también reduciendo la alucinación).
El desafío clave en la etapa de consulta es la recuperación, orquestación y razonamiento sobre bases de conocimientos (potencialmente muchas).
LlamaIndex proporciona módulos componibles que te ayudan a construir e integrar canalizaciones RAG para Q&A (motor de consulta), chatbot (motor de chat) o como parte de un agente.
Estos bloques de construcción se pueden personalizar para reflejar las preferencias de clasificación, así como componerse para razonar sobre múltiples bases de conocimientos de manera estructurada.
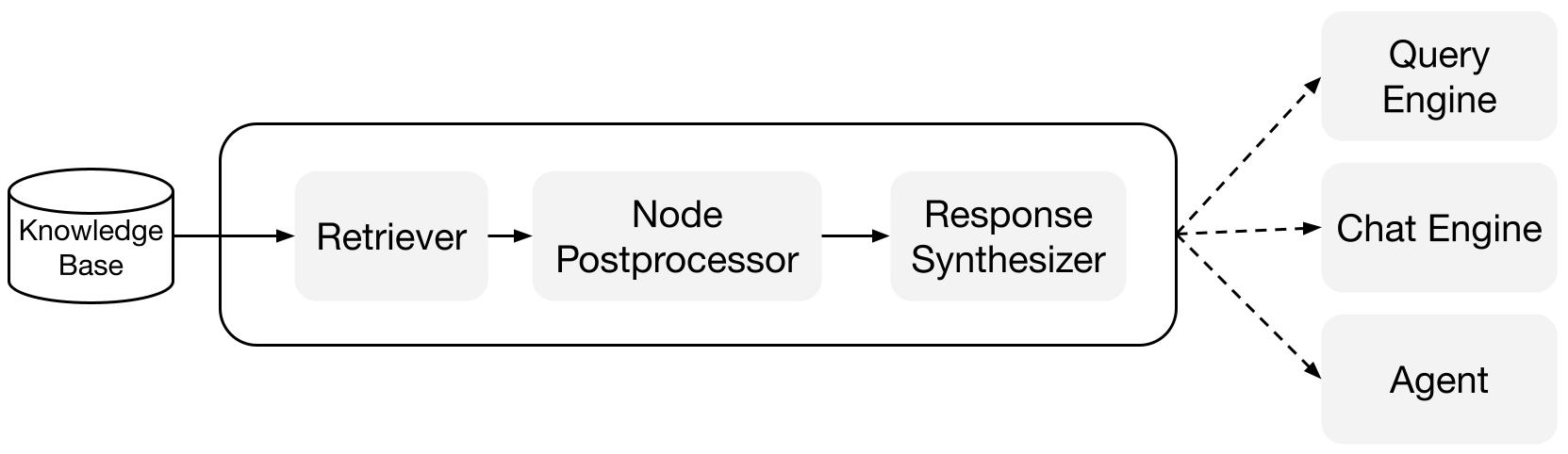
Bloques de Construcción
Recuperadores: Un recuperador define cómo recuperar de manera eficiente el contexto relevante de una base de conocimientos (es decir, índice) cuando se le proporciona una consulta. La lógica de recuperación específica difiere para diferentes índices, siendo la más popular la recuperación densa contra un índice vectorial.
Sintetizadores de Respuesta: Un sintetizador de respuesta genera una respuesta a partir de un LLM, utilizando una consulta del usuario y un conjunto dado de fragmentos de texto recuperados.
"
Canalizaciones
Motores de Consulta: Un motor de consulta es una canalización de extremo a extremo que te permite hacer preguntas sobre tus datos. Recibe una consulta en lenguaje natural y devuelve una respuesta, junto con el contexto de referencia recuperado y pasado al LLM.
Motores de Chat: Un motor de chat es una canalización de extremo a extremo para tener una conversación con tus datos (varias idas y vueltas en lugar de una sola pregunta y respuesta).
"